Abstract
Standard deep learning models for medical image analysis excel at learning correlational patterns but often fail to capture the underlying causal relationships inherent in disease pathology. This paper investigates a novel approach to enhance diagnostic accuracy by integrating principles of causal inference directly into a deep learning framework. We present a systematic study on the classification of retinal diseases from Optical Coherence Tomography (OCT) images using a ResNet18 architecture augmented with causality-aware modules. We explore two distinct mechanisms: a concatenation-based method ("Cat") and a feature-weighting method ("Mulcat"), along with different causality map computations (Lehmer mean vs. Max) and extraction modes (Full/Bool and Causes/Effects). Our key finding: a Mulcat model using a Lehmer-derived causality map with boolean weighting of causal features achieves 88.90% accuracy, demonstrating that selective integration of causal signals, rather than amplification, is the key to improved performance.
Introduction
Optical Coherence Tomography (OCT) provides high-resolution cross-sectional images of the retina, critical for diagnosing diabetic retinopathy, macular degeneration, and glaucoma. CNNs like ResNet have been widely applied to automate classification of these images, often matching human-level performance.
However, a fundamental limitation of traditional CNNs is their reliance on statistical correlations. These models recognize patterns without an explicit understanding of the cause-and-effect relationships that define disease progression. This "correlation, not causation" paradigm can lead to brittle models that struggle with out-of-distribution examples, a critical drawback in high-stakes medical applications.
Recent advances in causal inference offer a promising direction. By developing methods to estimate and integrate causal signals from data, it is possible to guide a neural network to learn features that are causally relevant, not merely correlated. This study presents a rigorous empirical analysis of causality-aware ResNet18 variants, uncovering a novel and counter-intuitive configuration that yields superior performance.
Methodology
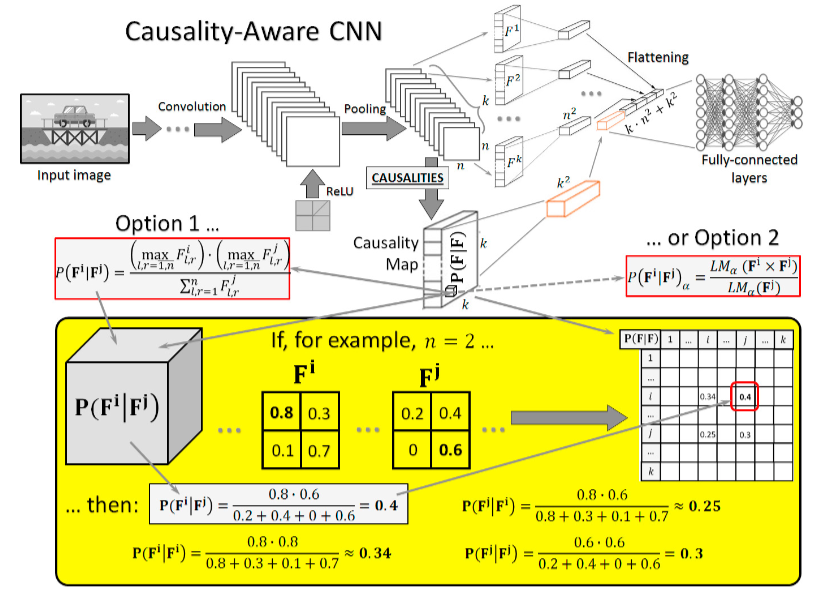
Our framework augments the ResNet18 backbone with specialized modules that process a computed "causality map", a k×k matrix where each element C(i,j) quantifies the causal influence of feature map Fi on Fj.
Causality Map Generation
After the image is processed by ResNet18's convolutional layers, two methods construct the causality map:
Max Method
A correlation-based proxy estimating causal influence by finding the maximum value in the feature interaction tensor. Computationally efficient but limited by its inability to distinguish direction of influence.
Lehmer Mean Method
A flexible, parameter-controlled mean that can be tuned to be more or less sensitive to feature interactions. Through fine-tuning, parameter p = 0 (geometric mean) was found optimal for training from scratch, suggesting multiplicative relationships best model feature influence in OCT analysis.
Causality-Aware Modules
Cat (Concatenate) Module
Flattens both the k feature maps and the k×k causality map into separate vectors, then concatenates them for the classifier. A passive strategy, the causal map is provided as supplementary metadata alongside visual features.
Mulcat (Multiply & Concatenate) Module
Uses the causality map to directly modulate feature maps via element-wise multiplication before classification. Controlled by two parameter pairs:
- Direction (Causes / Effects): Focus on root-cause features vs. downstream consequences
- Weighing Mode (Full / Bool): Continuous weighting vs. binary gating of causally relevant features
Experiments & Results
Lehmer Parameter Fine-Tuning
A preliminary experiment determined the optimal Lehmer parameter. Training from scratch with p = 0 achieved 91% accuracy, far outperforming other values and pretrained initializations.
| Lehmer Value (a) | Accuracy (Pretrained) | Accuracy (From Scratch) |
|---|---|---|
| 0 | 47% | 91% |
| 1 | 47% | 73% |
| -1 | 77% | 35% |
| -2 | 83% | 47% |
Main Classification Results
| Model | Factor Mode | Direction | Test Accuracy (%) |
|---|---|---|---|
| ResNet18 (baseline) | — | — | 93.63 |
| + Cat (Max) | — | — | 93.65 |
| + Cat (Lehmer) | — | — | 91.58 |
| + Mulcat (Max) | Full | Causes | 56.88 |
| + Mulcat (Max) | Full | Effects | 78.34 |
| + Mulcat (Max) | Bool | Effects | 83.69 |
| + Mulcat (Lehmer) | Full | Causes | 88.65 |
| + Mulcat (Lehmer) | Full | Effects | 74.48 |
| + Mulcat (Lehmer) | Bool | Causes | 88.90 |
| + Mulcat (Lehmer) | Bool | Effects | 86.04 |
Key Observation
The "Full" weighting mode, which directly amplifies features by their causal scores, consistently performs poorly, collapsing to 56.88% in the worst case. The "Bool" mode, treating causality as a selection gate rather than an amplifier, proves far more robust. More causal signal is not always better; selective integration is the key.
Discussion
The dramatic failure of the Full weighting mode suggests that raw causal scores are too noisy to be used as direct multipliers. Amplifying a single causally dominant feature biases the model, ignoring subtler visual cues that are also diagnostically relevant.
The Bool mode's success demonstrates that using causality as a selection mechanism, identifying which features matter, then weighting them equally, leads to more robust representations. The optimal direction (Causes over Effects) further aligns with clinical reasoning: identifying the root physiological cause is more valuable than detecting downstream consequences for accurate classification.
The geometric mean (p = 0) as the optimal Lehmer setting implies that multiplicative, rather than additive, relationships best capture how features interact in OCT retinal pathology.
Conclusion
This work demonstrates that the method of integrating causal information is critically important. Simple concatenation offers little benefit; aggressive amplification is detrimental; but nuanced, boolean-gated selection of causally relevant features based on the Lehmer geometric mean provides a highly competitive and interpretable result.
The identified configuration, Mulcat + Lehmer (p=0) + Bool + Causes, at 88.90% accuracy stands as the best causal variant and establishes a strong proof-of-concept for causality-aware representation learning in medical imaging. Future work will explore more sophisticated causality estimation methods, multi-modal extensions, and clinical validation of the discovered causal patterns.
References
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR.
- Terziyan, V., & Vitko, O. (2023). Causality-aware convolutional neural networks for advanced image classification and generation. Procedia Computer Science, 217, 495–506.
- Carloni, G., & Colantonio, S. (2024). Exploiting causality signals in medical images. Expert Systems with Applications, 249, 123433.
- Pearl, J. (2009). Causality: Models, Reasoning, and Inference. Cambridge University Press.
- Kermany, D. S., et al. (2018). Identifying Medical Diagnoses by Image-Based Deep Learning. Cell, 172(5), 1122–1131.
- Schölkopf, B. (2022). Causality for Machine Learning. arXiv:2206.14754.
Contact
For further information or collaboration opportunities:
Nikhileswara Rao Sulake,
nikhil01446@gmail.com ·
LinkedIn ·
GitHub